issue_comments
29 rows where issue = 1217759117 and user = 9599 sorted by updated_at descending
This data as json, CSV (advanced)
Suggested facets: reactions, created_at (date), updated_at (date)
issue 1
- Research: demonstrate if parallel SQL queries are worthwhile · 29 ✖
| id | html_url | issue_url | node_id | user | created_at | updated_at ▲ | author_association | body | reactions | issue | performed_via_github_app |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1114058210 | https://github.com/simonw/datasette/issues/1727#issuecomment-1114058210 | https://api.github.com/repos/simonw/datasette/issues/1727 | IC_kwDOBm6k_c5CZy3i | simonw 9599 | 2022-04-30T21:39:34Z | 2022-04-30T21:39:34Z | OWNER | Something to consider if I look into subprocesses for parallel query execution: https://sqlite.org/howtocorrupt.html#carrying_an_open_database_connection_across_a_fork
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research: demonstrate if parallel SQL queries are worthwhile 1217759117 | |
| 1112889800 | https://github.com/simonw/datasette/issues/1727#issuecomment-1112889800 | https://api.github.com/repos/simonw/datasette/issues/1727 | IC_kwDOBm6k_c5CVVnI | simonw 9599 | 2022-04-29T05:29:38Z | 2022-04-29T05:29:38Z | OWNER | OK, I just got the most incredible result with that! I started up a container running
And... the parallel one beat the non-parallel one decisively, on multiple page refreshes! Not parallel: 77ms Parallel: 47ms
So yeah, I'm very confident this is a problem with the GIL. And I am absolutely stunned that @colesbury's fork ran Datasette (which has some reasonably tricky threading and async stuff going on) out of the box! |
{
"total_count": 2,
"+1": 2,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research: demonstrate if parallel SQL queries are worthwhile 1217759117 | |
| 1112879463 | https://github.com/simonw/datasette/issues/1727#issuecomment-1112879463 | https://api.github.com/repos/simonw/datasette/issues/1727 | IC_kwDOBm6k_c5CVTFn | simonw 9599 | 2022-04-29T05:03:58Z | 2022-04-29T05:03:58Z | OWNER | It would be really fun to try running this with the in-development There's a Docker container for it: https://hub.docker.com/r/nogil/python It suggests you can run something like this: |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research: demonstrate if parallel SQL queries are worthwhile 1217759117 | |
| 1112878955 | https://github.com/simonw/datasette/issues/1727#issuecomment-1112878955 | https://api.github.com/repos/simonw/datasette/issues/1727 | IC_kwDOBm6k_c5CVS9r | simonw 9599 | 2022-04-29T05:02:40Z | 2022-04-29T05:02:40Z | OWNER | Here's a very useful (recent) article about how the GIL works and how to think about it: https://pythonspeed.com/articles/python-gil/ - via https://lobste.rs/s/9hj80j/when_python_can_t_thread_deep_dive_into_gil From that article:
That explains what I'm seeing here. I'm pretty convinced now that the reason I'm not getting a performance boost from parallel queries is that there's more time spent in Python code assembling the results than in SQLite C code executing the query. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research: demonstrate if parallel SQL queries are worthwhile 1217759117 | |
| 1112668411 | https://github.com/simonw/datasette/issues/1727#issuecomment-1112668411 | https://api.github.com/repos/simonw/datasette/issues/1727 | IC_kwDOBm6k_c5CUfj7 | simonw 9599 | 2022-04-28T21:25:34Z | 2022-04-28T21:25:44Z | OWNER | The two most promising theories at the moment, from here and Twitter and the SQLite forum, are:
A couple of ways to research the in-memory theory:
I need to do some more, better benchmarks using these different approaches. https://twitter.com/laurencerowe/status/1519780174560169987 also suggests:
I like that second idea a lot - I could use the mandelbrot example from https://www.sqlite.org/lang_with.html#outlandish_recursive_query_examples |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research: demonstrate if parallel SQL queries are worthwhile 1217759117 | |
| 1111726586 | https://github.com/simonw/datasette/issues/1727#issuecomment-1111726586 | https://api.github.com/repos/simonw/datasette/issues/1727 | IC_kwDOBm6k_c5CQ5n6 | simonw 9599 | 2022-04-28T04:17:16Z | 2022-04-28T04:19:31Z | OWNER | I could experiment with the Code examples: https://cs.github.com/?scopeName=All+repos&scope=&q=run_in_executor+ProcessPoolExecutor |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research: demonstrate if parallel SQL queries are worthwhile 1217759117 | |
| 1111725638 | https://github.com/simonw/datasette/issues/1727#issuecomment-1111725638 | https://api.github.com/repos/simonw/datasette/issues/1727 | IC_kwDOBm6k_c5CQ5ZG | simonw 9599 | 2022-04-28T04:15:15Z | 2022-04-28T04:15:15Z | OWNER | Useful theory from Keith Medcalf https://sqlite.org/forum/forumpost/e363c69d3441172e
So maybe this is a GIL thing. I should test with some expensive SQL queries (maybe big aggregations against large tables) and see if I can spot an improvement there. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research: demonstrate if parallel SQL queries are worthwhile 1217759117 | |
| 1111699175 | https://github.com/simonw/datasette/issues/1727#issuecomment-1111699175 | https://api.github.com/repos/simonw/datasette/issues/1727 | IC_kwDOBm6k_c5CQy7n | simonw 9599 | 2022-04-28T03:19:48Z | 2022-04-28T03:20:08Z | OWNER | I ran The area on the right is the threads running the DB queries:
Interactive version here: https://static.simonwillison.net/static/2022/datasette-parallel-profile.svg |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research: demonstrate if parallel SQL queries are worthwhile 1217759117 | |
| 1111683539 | https://github.com/simonw/datasette/issues/1727#issuecomment-1111683539 | https://api.github.com/repos/simonw/datasette/issues/1727 | IC_kwDOBm6k_c5CQvHT | simonw 9599 | 2022-04-28T02:47:57Z | 2022-04-28T02:47:57Z | OWNER | Maybe this is the Python GIL after all? I've been hoping that the GIL won't be an issue because the So I've been hoping this means that SQLite code itself can run concurrently on multiple cores even when Python threads cannot. But maybe I'm misunderstanding how that works? |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research: demonstrate if parallel SQL queries are worthwhile 1217759117 | |
| 1111681513 | https://github.com/simonw/datasette/issues/1727#issuecomment-1111681513 | https://api.github.com/repos/simonw/datasette/issues/1727 | IC_kwDOBm6k_c5CQunp | simonw 9599 | 2022-04-28T02:44:26Z | 2022-04-28T02:44:26Z | OWNER | I could try |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research: demonstrate if parallel SQL queries are worthwhile 1217759117 | |
| 1111661331 | https://github.com/simonw/datasette/issues/1727#issuecomment-1111661331 | https://api.github.com/repos/simonw/datasette/issues/1727 | IC_kwDOBm6k_c5CQpsT | simonw 9599 | 2022-04-28T02:07:31Z | 2022-04-28T02:07:31Z | OWNER | Asked on the SQLite forum about this here: https://sqlite.org/forum/forumpost/ffbfa9f38e |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research: demonstrate if parallel SQL queries are worthwhile 1217759117 | |
| 1111602802 | https://github.com/simonw/datasette/issues/1727#issuecomment-1111602802 | https://api.github.com/repos/simonw/datasette/issues/1727 | IC_kwDOBm6k_c5CQbZy | simonw 9599 | 2022-04-28T00:21:35Z | 2022-04-28T00:21:35Z | OWNER | Tried this but I'm getting back an empty JSON array of traces at the bottom of the page most of the time (intermittently it works correctly): ```diff diff --git a/datasette/database.py b/datasette/database.py index ba594a8..d7f9172 100644 --- a/datasette/database.py +++ b/datasette/database.py @@ -7,7 +7,7 @@ import sys import threading import uuid -from .tracer import trace +from .tracer import trace, trace_child_tasks from .utils import ( detect_fts, detect_primary_keys, @@ -207,30 +207,31 @@ class Database: time_limit_ms = custom_time_limit
|
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research: demonstrate if parallel SQL queries are worthwhile 1217759117 | |
| 1111597176 | https://github.com/simonw/datasette/issues/1727#issuecomment-1111597176 | https://api.github.com/repos/simonw/datasette/issues/1727 | IC_kwDOBm6k_c5CQaB4 | simonw 9599 | 2022-04-28T00:11:44Z | 2022-04-28T00:11:44Z | OWNER | Though it would be interesting to also have the trace reveal how much time is spent in the functions that wrap that core SQL - the stuff that is being measured at the moment. I have a hunch that this could help solve the over-arching performance mystery. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research: demonstrate if parallel SQL queries are worthwhile 1217759117 | |
| 1111595319 | https://github.com/simonw/datasette/issues/1727#issuecomment-1111595319 | https://api.github.com/repos/simonw/datasette/issues/1727 | IC_kwDOBm6k_c5CQZk3 | simonw 9599 | 2022-04-28T00:09:45Z | 2022-04-28T00:11:01Z | OWNER | Here's where read queries are instrumented: https://github.com/simonw/datasette/blob/7a6654a253dee243518dc542ce4c06dbb0d0801d/datasette/database.py#L241-L242 So the instrumentation is actually capturing quite a bit of Python activity before it gets to SQLite: And then: Ideally I'd like that |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research: demonstrate if parallel SQL queries are worthwhile 1217759117 | |
| 1111558204 | https://github.com/simonw/datasette/issues/1727#issuecomment-1111558204 | https://api.github.com/repos/simonw/datasette/issues/1727 | IC_kwDOBm6k_c5CQQg8 | simonw 9599 | 2022-04-27T22:58:39Z | 2022-04-27T22:58:39Z | OWNER | I should check my timing mechanism. Am I capturing the time taken just in SQLite or does it include time spent in Python crossing between async and threaded world and waiting for a thread pool worker to become available? That could explain the longer query times. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research: demonstrate if parallel SQL queries are worthwhile 1217759117 | |
| 1111553029 | https://github.com/simonw/datasette/issues/1727#issuecomment-1111553029 | https://api.github.com/repos/simonw/datasette/issues/1727 | IC_kwDOBm6k_c5CQPQF | simonw 9599 | 2022-04-27T22:48:21Z | 2022-04-27T22:48:21Z | OWNER | I wonder if it would be worth exploring multiprocessing here. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research: demonstrate if parallel SQL queries are worthwhile 1217759117 | |
| 1111551076 | https://github.com/simonw/datasette/issues/1727#issuecomment-1111551076 | https://api.github.com/repos/simonw/datasette/issues/1727 | IC_kwDOBm6k_c5CQOxk | simonw 9599 | 2022-04-27T22:44:51Z | 2022-04-27T22:45:04Z | OWNER | Really wild idea: what if I created three copies of the SQLite database file - as three separate file names - and then balanced the parallel queries across all these? Any chance that could avoid any mysterious locking issues? |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research: demonstrate if parallel SQL queries are worthwhile 1217759117 | |
| 1111535818 | https://github.com/simonw/datasette/issues/1727#issuecomment-1111535818 | https://api.github.com/repos/simonw/datasette/issues/1727 | IC_kwDOBm6k_c5CQLDK | simonw 9599 | 2022-04-27T22:18:45Z | 2022-04-27T22:18:45Z | OWNER | Another avenue: https://twitter.com/weargoggles/status/1519426289920270337
Doesn't look like there's an obvious way to access that from Python via the |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research: demonstrate if parallel SQL queries are worthwhile 1217759117 | |
| 1111485722 | https://github.com/simonw/datasette/issues/1727#issuecomment-1111485722 | https://api.github.com/repos/simonw/datasette/issues/1727 | IC_kwDOBm6k_c5CP-0a | simonw 9599 | 2022-04-27T21:08:20Z | 2022-04-27T21:08:20Z | OWNER | Tried that and it didn't seem to make a difference either. I really need a much deeper view of what's going on here. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research: demonstrate if parallel SQL queries are worthwhile 1217759117 | |
| 1111462442 | https://github.com/simonw/datasette/issues/1727#issuecomment-1111462442 | https://api.github.com/repos/simonw/datasette/issues/1727 | IC_kwDOBm6k_c5CP5Iq | simonw 9599 | 2022-04-27T20:40:59Z | 2022-04-27T20:42:49Z | OWNER | This looks VERY relevant: SQLite Shared-Cache Mode:
Enabled as part of the URI filename: Turns out I'm already using this for in-memory databases that have |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research: demonstrate if parallel SQL queries are worthwhile 1217759117 | |
| 1111460068 | https://github.com/simonw/datasette/issues/1727#issuecomment-1111460068 | https://api.github.com/repos/simonw/datasette/issues/1727 | IC_kwDOBm6k_c5CP4jk | simonw 9599 | 2022-04-27T20:38:32Z | 2022-04-27T20:38:32Z | OWNER | WAL mode didn't seem to make a difference. I thought there was a chance it might help multiple read connections operate at the same time but it looks like it really does only matter for when writes are going on. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research: demonstrate if parallel SQL queries are worthwhile 1217759117 | |
| 1111456500 | https://github.com/simonw/datasette/issues/1727#issuecomment-1111456500 | https://api.github.com/repos/simonw/datasette/issues/1727 | IC_kwDOBm6k_c5CP3r0 | simonw 9599 | 2022-04-27T20:36:01Z | 2022-04-27T20:36:01Z | OWNER | Yeah all of this is pretty much assuming read-only connections. Datasette has a separate mechanism for ensuring that writes are executed one at a time against a dedicated connection from an in-memory queue: - https://github.com/simonw/datasette/issues/682 |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research: demonstrate if parallel SQL queries are worthwhile 1217759117 | |
| 1111442012 | https://github.com/simonw/datasette/issues/1727#issuecomment-1111442012 | https://api.github.com/repos/simonw/datasette/issues/1727 | IC_kwDOBm6k_c5CP0Jc | simonw 9599 | 2022-04-27T20:19:00Z | 2022-04-27T20:19:00Z | OWNER | Something worth digging into: are these parallel queries running against the same SQLite connection or are they each rubbing against a separate SQLite connection? Just realized I know the answer: they're running against separate SQLite connections, because that's how the time limit mechanism works: it installs a progress handler for each connection which terminates it after a set time. This means that if SQLite benefits from multiple threads using the same connection (due to shared caches or similar) then Datasette will not be seeing those benefits. It also means that if there's some mechanism within SQLite that penalizes you for having multiple parallel connections to a single file (just guessing here, maybe there's some kind of locking going on?) then Datasette will suffer those penalties. I should try seeing what happens with WAL mode enabled. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research: demonstrate if parallel SQL queries are worthwhile 1217759117 | |
| 1111432375 | https://github.com/simonw/datasette/issues/1727#issuecomment-1111432375 | https://api.github.com/repos/simonw/datasette/issues/1727 | IC_kwDOBm6k_c5CPxy3 | simonw 9599 | 2022-04-27T20:07:57Z | 2022-04-27T20:07:57Z | OWNER | Also useful: https://avi.im/blag/2021/fast-sqlite-inserts/ - from a tip on Twitter: https://twitter.com/ricardoanderegg/status/1519402047556235264 |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research: demonstrate if parallel SQL queries are worthwhile 1217759117 | |
| 1111431785 | https://github.com/simonw/datasette/issues/1727#issuecomment-1111431785 | https://api.github.com/repos/simonw/datasette/issues/1727 | IC_kwDOBm6k_c5CPxpp | simonw 9599 | 2022-04-27T20:07:16Z | 2022-04-27T20:07:16Z | OWNER | I think I need some much more in-depth tracing tricks for this. https://www.maartenbreddels.com/perf/jupyter/python/tracing/gil/2021/01/14/Tracing-the-Python-GIL.html looks relevant - uses the |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research: demonstrate if parallel SQL queries are worthwhile 1217759117 | |
| 1111408273 | https://github.com/simonw/datasette/issues/1727#issuecomment-1111408273 | https://api.github.com/repos/simonw/datasette/issues/1727 | IC_kwDOBm6k_c5CPr6R | simonw 9599 | 2022-04-27T19:40:51Z | 2022-04-27T19:42:17Z | OWNER | Relevant: here's the code that sets up a Datasette SQLite connection: https://github.com/simonw/datasette/blob/7a6654a253dee243518dc542ce4c06dbb0d0801d/datasette/database.py#L73-L96 It's using
This is why Datasette reserves a single connection for write queries and queues them up in memory, as described here. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research: demonstrate if parallel SQL queries are worthwhile 1217759117 | |
| 1111390433 | https://github.com/simonw/datasette/issues/1727#issuecomment-1111390433 | https://api.github.com/repos/simonw/datasette/issues/1727 | IC_kwDOBm6k_c5CPnjh | simonw 9599 | 2022-04-27T19:21:02Z | 2022-04-27T19:21:02Z | OWNER | One weird thing: I noticed that in the parallel trace above the SQL query bars are wider. Mousover shows duration in ms, and I got 13ms for this query: But in the Given those numbers though I would expect the overall page time to be MUCH worse for the parallel version - but the page load times are instead very close to each other, with parallel often winning. This is super-weird. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research: demonstrate if parallel SQL queries are worthwhile 1217759117 | |
| 1111385875 | https://github.com/simonw/datasette/issues/1727#issuecomment-1111385875 | https://api.github.com/repos/simonw/datasette/issues/1727 | IC_kwDOBm6k_c5CPmcT | simonw 9599 | 2022-04-27T19:16:57Z | 2022-04-27T19:16:57Z | OWNER | I just remembered the Would explain why the first trace never seems to show more than three SQL queries executing at once. |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research: demonstrate if parallel SQL queries are worthwhile 1217759117 | |
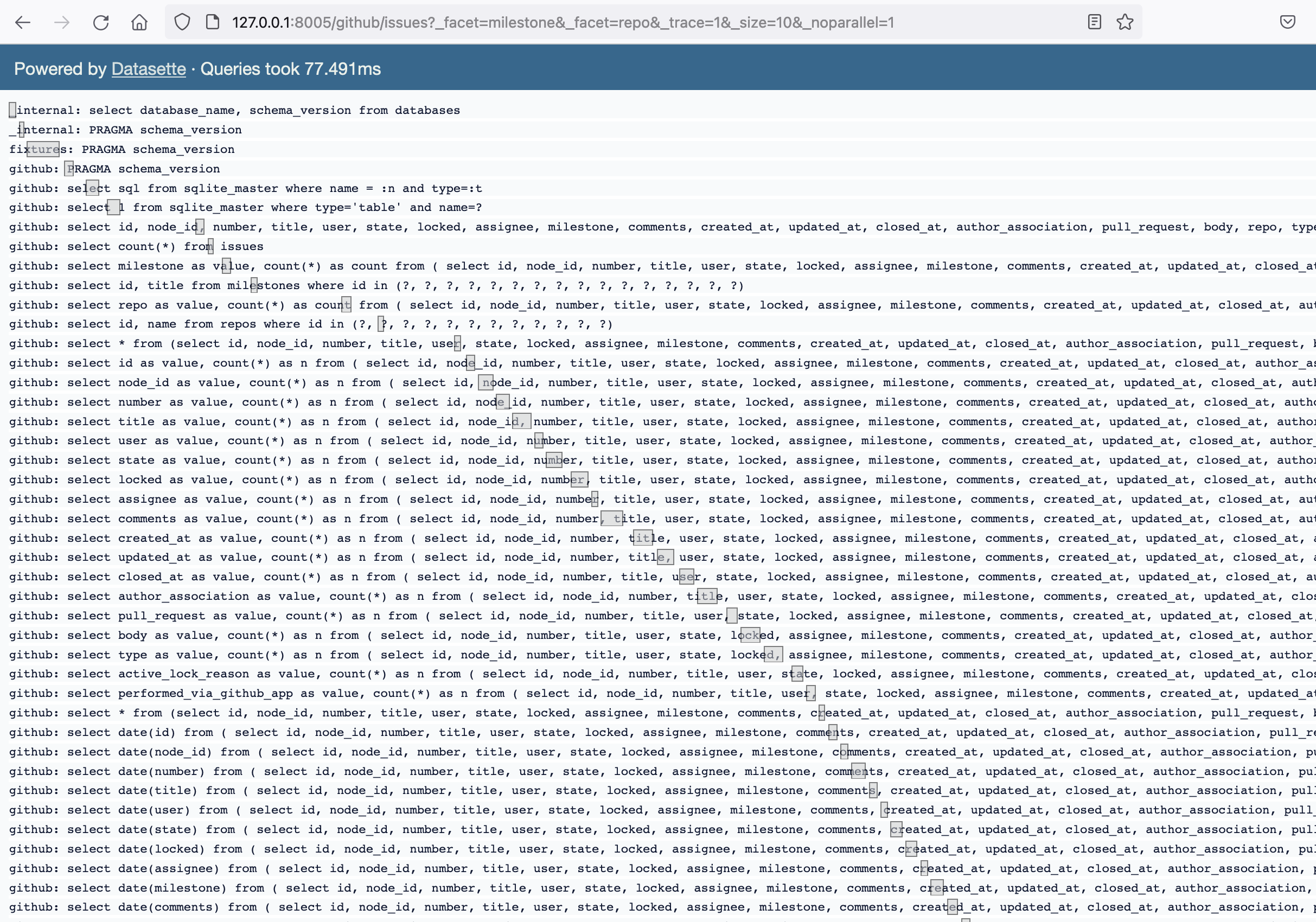
| 1111380282 | https://github.com/simonw/datasette/issues/1727#issuecomment-1111380282 | https://api.github.com/repos/simonw/datasette/issues/1727 | IC_kwDOBm6k_c5CPlE6 | simonw 9599 | 2022-04-27T19:10:27Z | 2022-04-27T19:10:27Z | OWNER | Wrote more about that here: https://simonwillison.net/2022/Apr/27/parallel-queries/ Compare https://latest-with-plugins.datasette.io/github/commits?_facet=repo&_facet=committer&_trace=1
With the same thing but with parallel execution disabled:
Those total page load time numbers are very similar. Is this parallel optimization worthwhile? Maybe it's only worth it on larger databases? Or maybe larger databases perform worse with this? |
{
"total_count": 0,
"+1": 0,
"-1": 0,
"laugh": 0,
"hooray": 0,
"confused": 0,
"heart": 0,
"rocket": 0,
"eyes": 0
} |
Research: demonstrate if parallel SQL queries are worthwhile 1217759117 |




{kind=link}
Advanced export
JSON shape: default, array, newline-delimited, object
CREATE TABLE [issue_comments] (
[html_url] TEXT,
[issue_url] TEXT,
[id] INTEGER PRIMARY KEY,
[node_id] TEXT,
[user] INTEGER REFERENCES [users]([id]),
[created_at] TEXT,
[updated_at] TEXT,
[author_association] TEXT,
[body] TEXT,
[reactions] TEXT,
[issue] INTEGER REFERENCES [issues]([id])
, [performed_via_github_app] TEXT);
CREATE INDEX [idx_issue_comments_issue]
ON [issue_comments] ([issue]);
CREATE INDEX [idx_issue_comments_user]
ON [issue_comments] ([user]);
user 1